生成AIから自社サイトを守るためのrobots.txt設定法

生成AIが急速に発展する中、多くの企業サイトが「知らないうちに AI クローラーに情報を収集されている」状況が生まれています。Web上のテキストや画像は学習データとして利用されやすく、オリジナルコンテンツが AI に模倣されたり、競合サービスに分析されるリスクも無視できません。
こうした背景から、いま注目されているのが robots.txt を使った AI クローラー対策 です。
検索エンジンのクロールは許可しつつ、生成AIだけをブロックすることも可能で、導入も非常にシンプル。ただし、robots.txt にできること・できないことを正しく理解しないと、意図しない情報漏れが起こる場合もあります。
本記事では、生成AIから自社サイトを守るための robots.txt の設定方法を、具体的なコード例とともにわかりやすく解説します。
なぜ生成AI対策が必要なのか?
生成AIは便利さと引き換えに、企業サイトのコンテンツを無断で収集・学習するリスクを抱えています。特に近年は、AI専用のクローラーが増加しており、知らないうちに自社のテキスト・画像・構造データが取得され、学習データとして利用されるケースが増えています。
もし対策を取らなければ、オリジナル記事がAIに要約・再生成されて拡散されたり、競合サービスに解析されることで、ブランド価値の低下や情報漏えいの危険性が高まります。だからこそ、企業やメディア運営者にとって「生成AI対策」は、SEOやセキュリティと同じく、今すぐ考えるべき重要なテーマとなっています。
関連記事:AIO・LLMO対策をコーポレートサイトで行う方法は?
AIクローラーのデータ収集の仕組み
AIクローラーは、検索エンジンのクローラーと同じようにWebサイトを巡回し、ページ内のテキスト、画像、リンク構造などの情報を収集します。収集したデータは、生成AIモデルの学習や精度向上、回答内容の改善に利用されます。特に最近は、GPTBot(OpenAI)、Google-Extended、Claude-Web(Anthropic)など“生成AI専用”のクローラーが増えており、これらは検索エンジンとは異なる目的で情報を取得します。
一般的な挙動としては「まず robots.txt を確認 → 許可された範囲をクロール」という流れをとりますが、すべてのAIクローラーが厳密に従うわけではありません。また、一瞬で大量のページを取得できるため、対策をしないまま放置すると、意図しないコンテンツが学習データとして利用される可能性があります。
つまり、AIクローラーは従来の検索クローラーと似ていても、収集した情報の使われ方が根本的に異なるため、企業サイトにとっては適切な制御が必要になるのです。
robots.txtでAIクローラーをブロックできるのか?
生成AIクローラーは、基本的に Web サイトの最上位にある robots.txt を確認し、アクセス可能な範囲を判断します。そのため、多くの AI クローラーは robots.txt を利用したブロックに対応しており、意図しない学習利用を防ぐ一歩目として有効です。
しかし同時に、「robots.txt に書けば完全に防げる」というわけではありません。各 AI 企業の遵守姿勢には違いがあり、未知のクローラーや非公開の収集ツールも存在します。つまり、robots.txt は効果的でありながら、限界も理解して運用する必要があります。
この章では、robots.txt がAIクローラーにどこまで効くのか、その仕組みと現実的な注意点を整理していきます。
検索エンジンのクロールは許可しつつAIだけ拒否できる?
結論から言うと、検索エンジンのクロールは許可しつつ、生成AIクローラーだけを拒否することは可能です。
robots.txt はクローラーごとにルールを分けて記述できるため、Googlebot や Bingbot といった検索エンジンのクロールはそのまま許可し、GPTBot や Google-Extended など AI 学習用のクローラーだけをブロックする、といった制御ができます。
たとえば、Google の検索エンジン(Googlebot)は許可しつつ、AI学習用の Google-Extended のみをブロックするといった設定が可能です。
ただし注意すべき点は以下の通りです。
- AI クローラーの名称(User-agent)は頻繁に増える/変わる
→ 新しいクローラーが登場したら随時追加が必要。 - 未知のクローラーや非公開の学習ツールは robots.txt を無視する可能性がある
→ 公開されていない収集には対応できない。 - AI クローラー=検索結果とは無関係
→ 検索順位には影響しないが、AIの回答内容には反映され得る。
とはいえ、明確に公開されている AI クローラーに対しては robots.txt の拒否設定が有効で、検索エンジンのクロールを損なうことなく、生成AIだけを選択的に制御できるのが特徴です。
主要AIクローラー一覧とブロック推奨設定
生成AIの普及に伴い、各社が独自の AI クローラーを公開し、Web上のデータを収集するケースが増えています。これらのクローラーは従来の検索エンジンとは目的も仕組みも異なり、「検索ランキングには関わらないが、学習データには利用される」という特徴があります。
そのため、自社サイトの内容を勝手にAI学習へ利用されたくない場合は、どのクローラーが存在しているのかを把握し、robots.txt で適切に制御することが重要です。ここでは、現在公開されている主要なAIクローラーと、それぞれをブロックするための推奨設定を一覧でまとめます。
GPTBot(OpenAI)からアクセスをブロックする設定
robots.txt に以下を追加することでGPTBot(OpenAI)からのアクセスをブロックできます。
User-agent: GPTBot
Disallow: /Claude-Web(Anthropic)からアクセスをブロックする設定
robots.txt に以下を追加することでGPTBot(OpenAI)からのアクセスをブロックできます。
User-agent: ClaudeBot
Disallow: /PerplexityBot(Anthropic)からアクセスをブロックする設定
robots.txt に以下を追加することでGPTBot(OpenAI)からのアクセスをブロックできます。
User-agent: PerplexityBot
Disallow: /各社のrobots.txtの設定内容
各社のrobots.txtではAIクローラーへの対策をどのように行なっているか実際のrobots.txtを確認してみます。
meta社のrobots.txt
facebook.com
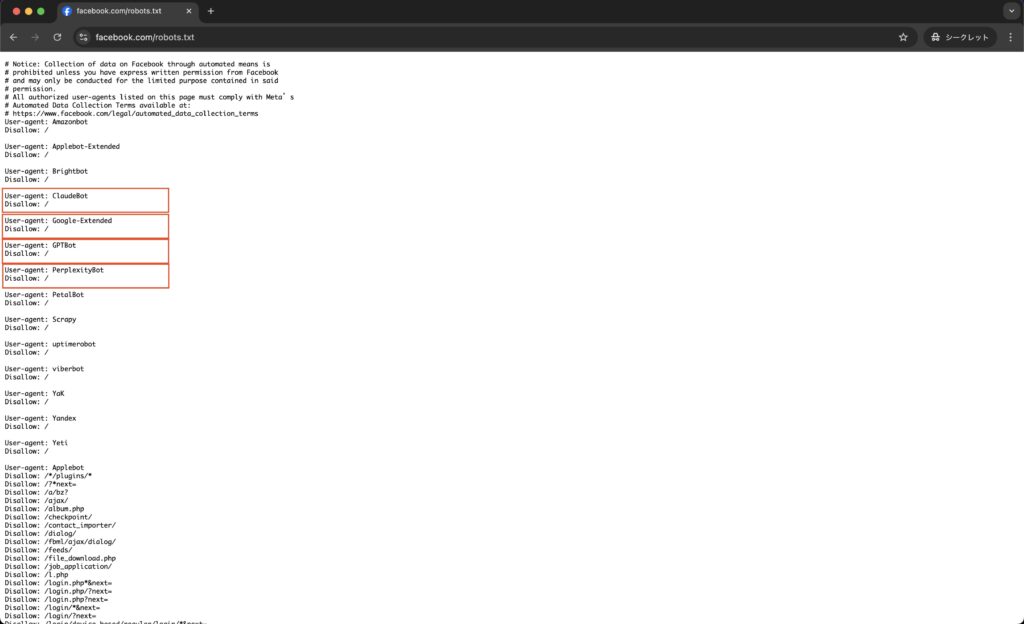
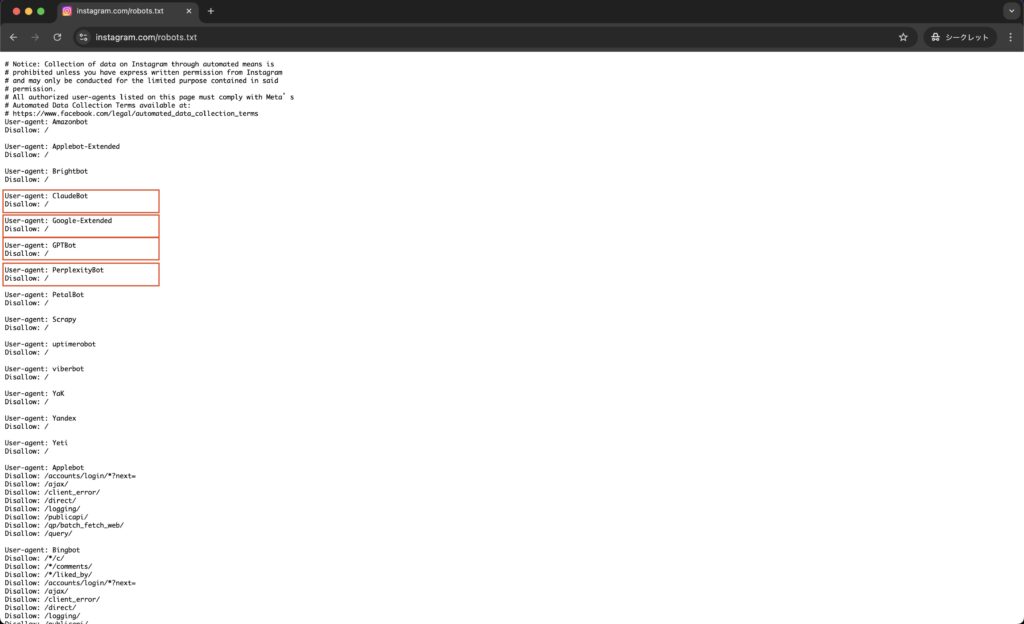
instagram.com
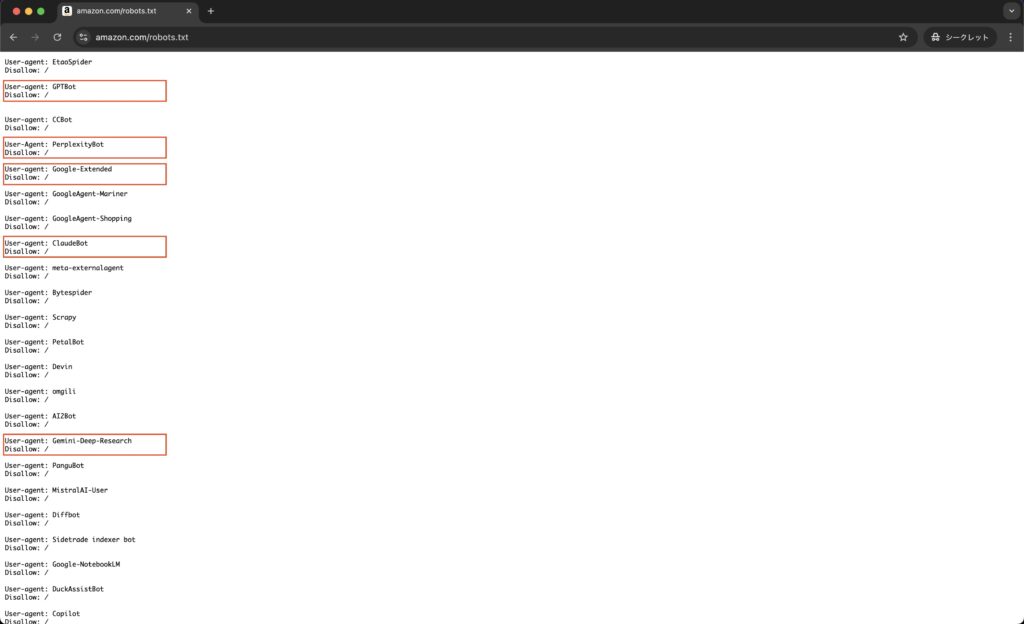
Amazonのrobots.txt
生成AI時代のWebサイト防衛は継続的アップデートが必要
AIクローラーは日々、増加するし変更も多々あります。普段から最新情報を把握し、robots.txt変更を行いましょう。データの収集がされるとAIの検索結果で自社サイトの内容が表示され集客に繋がりますが、記事の無断コピーなど予期せぬ情報を学習されないよう対策をしていきましょう。